Einleitung
Nach meinem letzten Jobinterview für eine Data-Analyst-/BI-Rolle im COO-Umfeld war mir klar: Ich möchte nicht nur über Datenarchitekturen, KPIs und Planung reden – ich möchte sie mir selbst bauen.
In den letzten Jahren habe ich viel mit Daten gearbeitet: in der klinischen Forschung, in einem Tech-Start-up und in einem regulierten Laborumfeld. Ich habe Datenpipelines entwickelt, Dashboards gebaut und verteilte Datenquellen in konsistentere Strukturen überführt. Trotzdem hatte ich das Gefühl, dass ein Puzzleteil fehlt: ein durchgängiges BI-Szenario, das Operations, Reporting und erste Planungsideen zusammenbringt – so, wie es in modernen XP&A-Landschaften gedacht ist.
Dieser Blogpost ist der Startpunkt eines solchen Projekts. Hier geht es weniger um Code, sondern um die Reise von der Idee zur Architektur. Die technischen Details folgen in einem eigenen Projekt-Post, sobald das System steht.
Ausgangspunkt: Incident-Management als Inspiration
Die Inspiration kam aus einem meiner letzten Tätigkeitsfelder: dem Incident- und Servicemanagement in einem regulierten IT-/Laborumfeld.
Dort habe ich erlebt:
- wie unterschiedlich Teams über die gleichen Incidents sprechen können,
- wie schnell man sich in Details verliert,
- und wie schwer es ist, ohne konsistente Kennzahlen die richtige Priorisierung zu treffen.
Gleichzeitig gab es viele Daten: Tickets, Kategorien, Bearbeitungszeiten, betroffene Systeme, beteiligte Teams. Alles Zutaten für ein sinnvolles Operations-Reporting – aber in der Praxis oft zersplittert in Tools, Excel-Exporten und individuellen Auswertungen.
Genau hier entstand meine Projektidee: Was wäre, wenn ich mir ein eigenes, kleines Operations-Cockpit baue – mit einer klaren Datenbasis, standardisierten KPIs und einem Dashboard, das typische Service- und Operationsfragen beantwortet?
Von der Idee zur Skizze: Was soll das System können?
Ich habe mir zunächst ganz bewusst nicht über Tools Gedanken gemacht, sondern über Fragen:
- Wie viele Tickets kommen pro Woche rein – und wie entwickelt sich das über die Zeit?
- Wie schnell werden Tickets gelöst? Wie hoch ist die SLA-Erfüllungsquote?
- Wie ist die Auslastung der Teams verteilt?
- Gibt es Muster nach Ticketkategorie, Priorität oder System?
- Und: Was passiert, wenn das Ticketvolumen steigt – kann die aktuelle Kapazität das noch auffangen?
Aus diesen Fragen ist eine erste Skizze entstanden:
1. Datenschicht
- Eine relationale Datenbank auf meinem eigenen Server,
- Tabellen für Tickets, Teams, Projekte und Kalender,
- klar definierte Felder und Beziehungen.
2. Modell- & Business-Schicht
Standardisierte Kennzahlen (KPIs):
- Ticketvolumen, Bearbeitungsdauer, SLA-Quote, Backlog-Größe, Workload pro Team,
- später auch einfache Forecasts für das Ticketvolumen.
- Eine saubere Trennung von Rohdaten und Auswertungsebene – eine kleine „Single Source of Truth" für dieses Szenario.
3. Visualisierungs- & Planungsschicht
- Ein Power-BI-Dashboard für Reporting und Visualisierung,
- perspektivisch eine Anbindung an eine Planungsplattform (board),
- um das Szenario in Richtung XP&A zu erweitern: Ist-Daten, Forecasts und einfache Planungsideen miteinander zu verknüpfen.
An der Stelle habe ich zum ersten Mal gemerkt, wie sehr mich diese Architekturlandschaft fasziniert: Daten fließen von der Entstehung (Incidents, Projekte) über modellierte Strukturen in Kennzahlen, die wiederum als Grundlage für Forecasts, Planung und Entscheidungen dienen.
Brücke zu meinen bisherigen Erfahrungen
Das Projekt ist kein losgelöster Spielplatz, sondern bündelt vieles, was ich bisher gemacht habe, in einem neuen Kontext:
Forschung / Bioinformatik
Dort habe ich Datenpipelines für komplexe OMICS-Daten aufgebaut und interaktive Dashboards und Tools (z.B. mit R Shiny) entwickelt, damit Kliniker:innen mit den Ergebnissen arbeiten können. Die Idee, aus Rohdaten wiederverwendbare „Data Products" zu machen, kommt genau von dort.
Start-up / Wirtschaftlichkeit
Im Start-up-Umfeld habe ich ein Dashboard aufgebaut, das Erträge und Amortisationszeiten eines Antennennetzwerks sichtbar gemacht hat. Hier habe ich gelernt, wie mächtig schon einfache KPIs wie „Time-to-Revenue" für Management-Entscheidungen sein können.
Reguliertes IT-/Laborumfeld
In meiner letzten Rolle habe ich Datenmodelle und ETL-Prozesse in einer validierten Umgebung verantwortet. Dev-/Test-/Produktiv-Systeme, Freigabeprozesse und Datenqualität waren zentrale Themen. Genau dieser Qualitätsanspruch soll auch in meinem eigenen kleinen BI-Projekt gelten – nur eben in einem kontrollierten, selbstgebauten Setup.
Dieses neue Projekt ist für mich ein logischer nächster Schritt: Ich übertrage die Prinzipien aus Forschung, Start-up und regulierter IT in ein eigenes Operations-Szenario und kombiniere sie mit einer modernen BI-/Planungsarchitektur.
Wie ich bei der Umsetzung vorgehe
Ich habe mich bewusst dafür entschieden, das Projekt schrittweise aufzubauen – und jede Stufe für sich funktionsfähig zu machen:
1. Datenbank & Datendesign
- Entwurf eines relationalen Schemas (Tickets, Teams, Projekte, Kalender),
- Implementierung auf einem eigenen Server,
- Generierung realistischer, synthetischer Daten (z.B. mit Python).
2. Data-Model & KPIs
- Aufbau eines sternförmigen Datenmodells,
- Definition und Dokumentation der wichtigsten KPIs: Ticketvolumen, durchschnittliche Bearbeitungszeit, SLA-Quote, Backlog, Workload, einfache Forecast-Kennzahlen.
- Ziel: Eine kleine, aber klare Single Source of Truth.
3. Power BI: Operations-Cockpit
- Anbindung an die Datenbank,
- Aufbau eines Dashboards mit mehreren Sichten: Executive Overview, Operations & Capacity, Projekte & Planung.
4. Erweiterung in Richtung XP&A mit board
Im nächsten Schritt möchte ich eine Planungsplattform (board) einbinden:
- Power BI nutzt die Ist-Daten und KPIs,
- board nutzt dieselben Strukturen für Plan- und Forecastwerte,
- beide teilen sich die gleiche Datenbasis, um eine integrierte Sicht auf Ist, Plan und Forecast zu ermöglichen.
- Dieser Teil wird experimenteller und bekommt später einen eigenen, technischen Projekt-Post.
5. Dokumentation & Reflexion
- Begleitend dokumentiere ich alle Schritte – von der ersten Skizze über das Datenmodell bis zum fertigen Dashboard – in einem zweiten, technischen Beitrag.
- Dieser erste Post hier ist bewusst konzeptionell und soll zeigen, wie aus einer Idee eine Architektur wird.
Warum ich dieses Projekt teile
Zum einen, weil ich glaube, dass man über Datenarchitektur und BI viel lernen kann, wenn man sich seine eigenen Szenarien baut – ohne Kundendaten, ohne reale Zwänge, aber mit einem klaren Qualitätsanspruch.
Zum anderen, weil dieses Projekt ein Stück weit meine eigene berufliche Entwicklung widerspiegelt:
- von der wissenschaftlichen Analyse hin zu wiederverwendbaren Data Products,
- von ad-hoc-Dashboards hin zu definierten KPIs und Single-Source-of-Truth-Denken,
- und von isolierten Analysen hin zu der Frage, wie sich Reporting, Forecast und Planung in einer integrierten Architektur zusammensetzen.
Im nächsten Beitrag werde ich konkreter: mit dem Datenmodell, mit den konkreten KPI-Definitionen, mit Screenshots aus Power BI, und – soweit es möglich ist – mit einem ersten Prototypen in board.
Bis dahin freue ich mich über Feedback, Ideen oder Austausch – insbesondere von Menschen, die selbst an der Schnittstelle zwischen Operations, BI und Planung arbeiten.
Was als Nächstes kommt
Im nächsten Schritt werde ich:
- die Datenbankstruktur implementieren,
- synthetische Daten generieren,
- und das erste Version des Operations-Cockpits in Power BI aufbauen.
Sobald das steht, folgt hier der technische Deep Dive.
Überblick
Dieser Abschnitt beschreibt die wichtigsten Stolpersteine auf dem Weg von der leeren Datenbank bis zur angebundenen Power-BI-Instanz – immer im Muster Problem ➝ Analyse ➝ Lösung.
Problem 1: Die Date-Dimension ist da – aber nicht wirklich
Problem
Im psql sah die Tabelle dim_date zunächst „gesund" aus, trotzdem schlug das Python-Skript beim Befüllen der Faktentabelle mit einer Foreign-Key-Verletzung fehl:
Key (created_date_id)=(2023-01-01) is not present in table "dim_date".
Analyse
\dt ops.*zeigte: Die Tabelle existiert, aber nur im Schemaops.- Ein Blick auf die Inhalte ergab:
MIN(date_id) = 2025-12-08,MAX(date_id) = 2025-12-09– also nur zwei Tage, vermutlich von einem Testlauf. - Das Python-Skript generierte Tickets ab
2023-01-01– diese Daten konnte die Date-Dimension schlicht nicht abdecken.
Lösung
Die Lösung war weniger „Bugfix" als ein kleiner Reset in der richtigen Reihenfolge:
- Fact-Tabelle
fact_ticketleeren. - Foreign Keys von
fact_ticketaufdim_datetemporär entfernen. - dim_date komplett neu befüllen – diesmal als lückenlose Kalenderdimension von
2023-01-01bis2026-12-31. - Foreign Keys wieder hinzufügen.
- Tickets erneut generieren.
Ergebnis: Die Kalenderdimension deckt jetzt den gesamten Zeitraum der Tickets ab, und die Foreign-Key-Constraints sichern diese Konsistenz langfristig ab.
Problem 2: Python spricht mit PostgreSQL – aber PostgreSQL will ein Passwort
Problem
Beim ersten Start des Generators aus der virtuellen Umgebung meldete psycopg2:
fe_sendauth: no password supplied
Analyse
- Die Verbindung im Skript lief über TCP zu
localhost:5432. - Der verwendete DB-User war so konfiguriert, dass ein Passwort zwingend erforderlich ist.
- Im Skript stand jedoch ein leerer
DB_PASSWORD-Wert.
Lösung
- In PostgreSQL ein sicheres Passwort für den verwendeten User gesetzt.
- DB-Konfiguration im Skript entsprechend angepasst.
- Verbindung erneut getestet – ab dann lief der Ticket-Generator stabil durch.
Der Nebeneffekt ist positiv: Das Projekt nutzt dieselben Sicherheitsstandards, die ich auch in produktiven Umgebungen erwarten würde.
Problem 3: Power BI mag Self-Signed „snakeoil"-Zertifikate nicht
Problem
Die direkte Anbindung von Power BI an PostgreSQL schlug mit einer SSL-Fehlermeldung fehl:
"Das Remotezertifikat ist laut Validierungsverfahren ungültig."
Analyse
SHOW ssl;ergab: SSL ist aktiviert.SHOW ssl_cert_file;zeigte das Standard-„snakeoil"-Zertifikat – ein Self-Signed-Cert, das Windows (zurecht) nicht vertraut.- Power BI bietet im verwendeten Dialog keine einfache Möglichkeit, das Zertifikat einfach „blind zu vertrauen".
Lösung
Statt SSL global abzuschalten, habe ich einen kleinen, aber sauberen PKI-Weg gewählt:
- Eine eigene, lokale Root-CA erzeugt.
- Ein Server-Zertifikat für die IP
167.86.108.37damit signiert. - PostgreSQL so konfiguriert, dass es genau dieses Zertifikat nutzt.
- Das CA-Zertifikat (
myCA.pem) auf dem Windows-Client als vertrauenswürdige Stammzertifizierungsstelle importiert. - In Power BI die alten Anmeldeinformationen zur Datenquelle entfernt und die Verbindung neu aufgebaut.
Danach war die Fehlermeldung verschwunden, und das Schema ops ließ sich in Power BI wie geplant importieren.
Was ich aus der Problemkette mitnehme
Rückblickend waren die Probleme nicht spektakulär – aber sie sind typisch für ein End-to-End-BI-Projekt:
- Dimensionstabellen, die nicht zum Zeitraum der Fakten passen.
- Security-Vorgaben (Passwörter, SSL), die erst dann auffallen, wenn Tools sie ernst nehmen.
- Feinheiten in Tools wie psql oder Power BI, die man nur einmal falsch machen muss.
Der entscheidende Punkt ist für mich die Problem ➝ Analyse ➝ Lösung-Mentalität: nicht „irgendwie" weiter machen, wenn ein Fehler kommt, sondern systematisch verstehen, wo im Stack das Problem sitzt, und die Architektur so verbessern, dass das Problem nicht wiederkommt.
Vom Datenmodell zum Dashboard
Nachdem Datenbank, Dim-Tabellen und Ticket-Generator standen, ging es darum, das Ganze in ein nutzbares Operations-Cockpit zu übersetzen. Dafür habe ich Power BI direkt an das ops-Schema der PostgreSQL-Datenbank angebunden und das Sternschema 1:1 übernommen.
Der Kern des Modells besteht aus:
ops_fact_ticketals Faktentabelle für alle Tickets,ops_dim_dateals Kalenderdimension (inkl. Jahr, Monat, Wochentag usw.),ops_dim_teamfür die operativen Teams,ops_dim_userfür die einzelnen Bearbeiter:innen.
Datenmodell & Diamond-Model
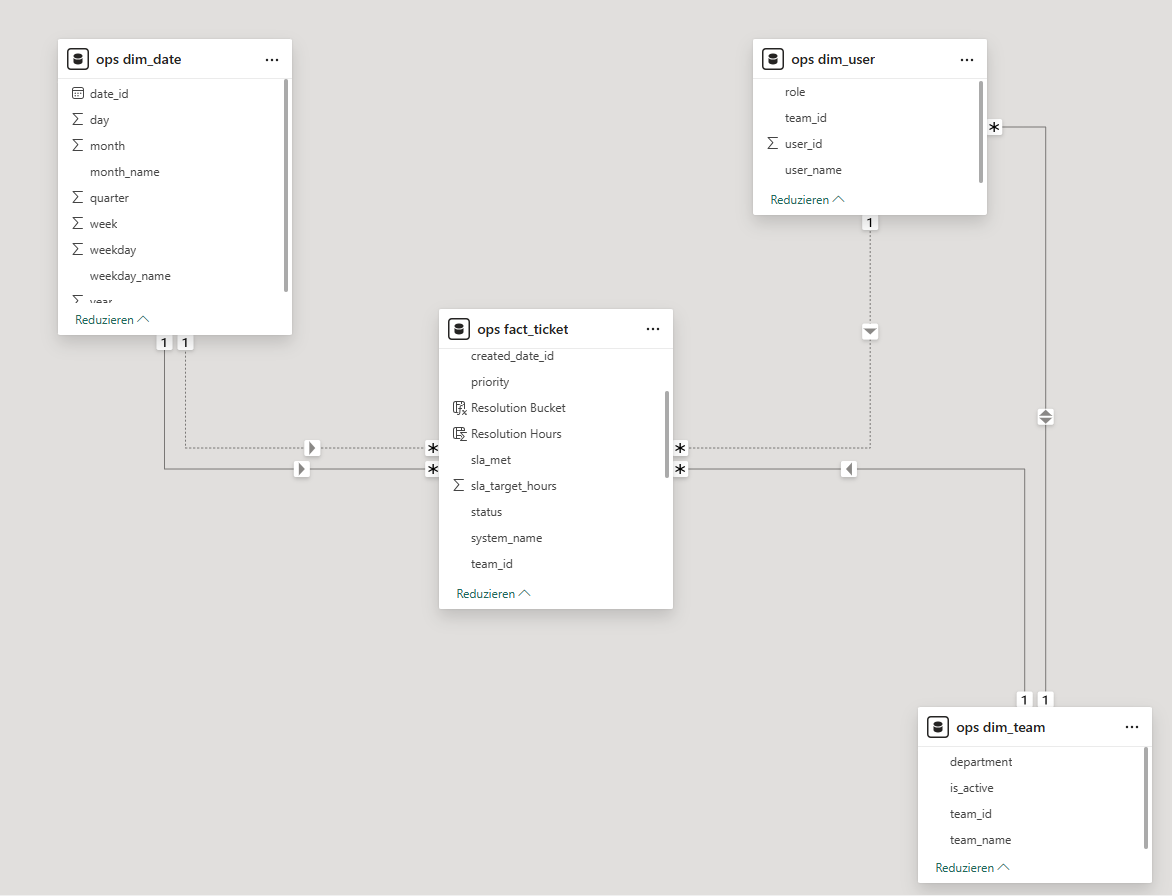
Abbildung 1: Entity-Relationship-Diagramm und Diamond-Model-Schema des Operations-Cockpits.
Seite 1 – KPI Overview
Die erste Seite des Reports ist bewusst als „Executive Overview" gestaltet. Drei Kennzahlen stehen im Mittelpunkt:
- Total Tickets – Anzahl der Tickets im aktuellen Filterkontext,
- Avg Resolution Hours – durchschnittliche Bearbeitungszeit in Stunden,
- SLA Rate (%) – Anteil der Tickets, die innerhalb ihrer Zielzeit gelöst wurden.
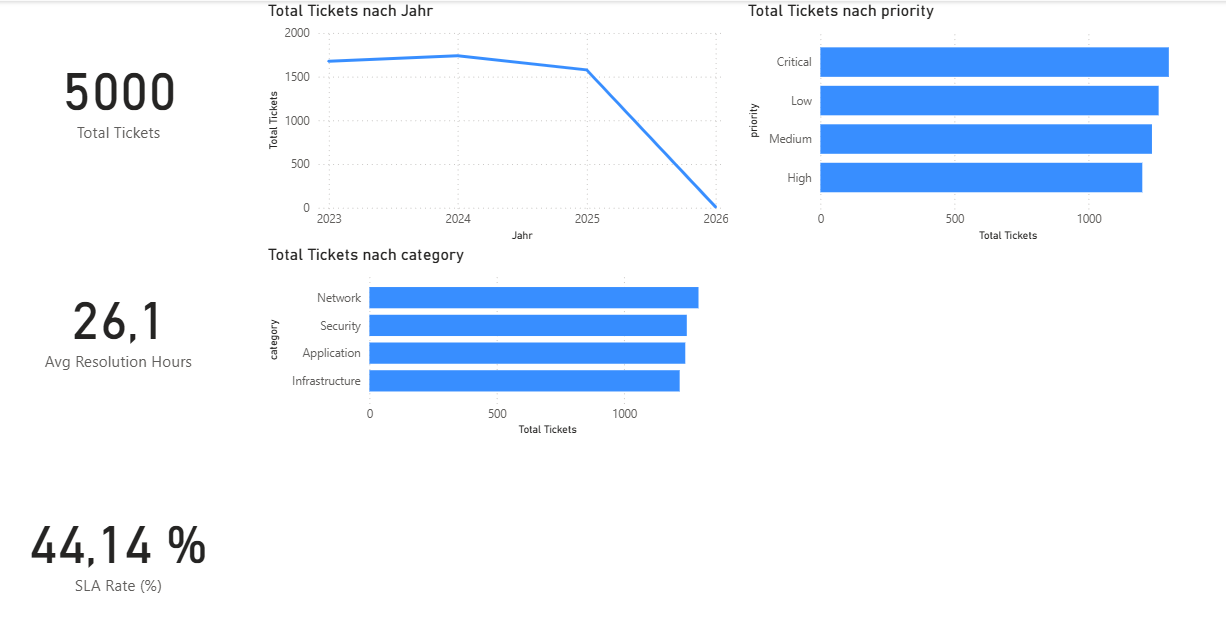
Abbildung 2: KPI Overview – Executive Dashboard mit Tickets, SLA-Rate und Zeitreihen.
Seite 2 – Operations & Capacity
Die zweite Seite zoomt eine Ebene tiefer und schaut auf Teams und Kapazität. Drei Balkendiagramme bilden dabei das Rückgrat der Seite:
- Tickets pro Team ➝ Workload-Verteilung,
- SLA Rate pro Team ➝ Qualitätsvergleich zwischen Teams,
- Avg Resolution Hours pro Team ➝ Bearbeitungsgeschwindigkeit je Team.
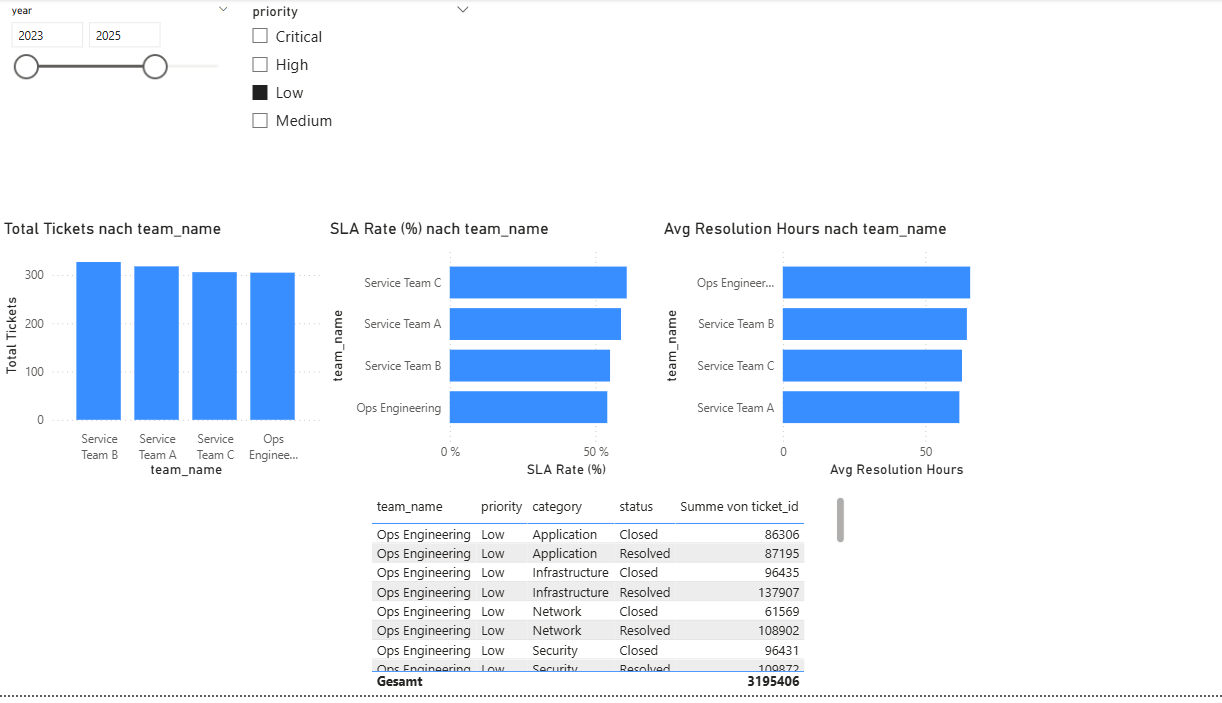
Abbildung 3: Operations & Capacity – Auslastung, SLA-Rate und Bearbeitungsdauer pro Team.
Seite 3 – Ticket Lifecycle & SLA
Die dritte Seite konzentriert sich stärker auf den Ticketlebenszyklus und die Qualität der Bearbeitung:
- Eine Linie zeigt die Entwicklung der SLA Rate (%) über die Zeit.
- Ein Diagramm mit Resolution Buckets (0–4 h, 4–8 h, …) visualisiert die Verteilung der Bearbeitungszeiten.
- Ein gestapeltes Balkendiagramm trennt SLA-konforme und SLA-verletzende Tickets nach Priority.
Python-Visual: Verteilung der Bearbeitungszeit
Auf dieser Seite nutze ich außerdem ein Python-Visual. Power BI übergibt die Felder priority und Resolution Hours als DataFrame dataset. Ein kurzes Python-Skript erzeugt daraus einen Boxplot der Bearbeitungszeit pro Priority – inklusive defensiver Checks.
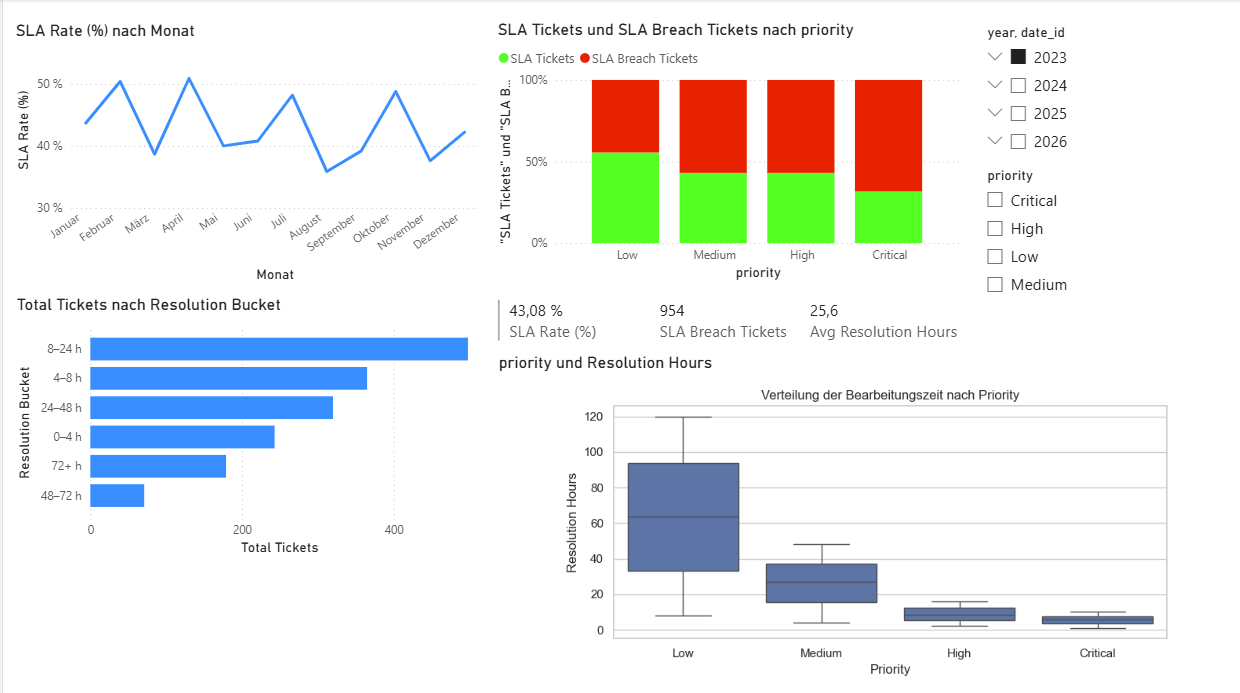
Abbildung 4: Ticket Lifecycle & SLA – inklusive Python-gestützter Verteilungsanalyse.
Warum diese Architektur sinnvoll ist
Das Setup ist bewusst klein, aber vollständig:
- Eine relationale Datenbasis mit klar definierten Schlüsseln,
- ein einfaches, aber sauberes Sternschema für Power BI,
- standardisierte KPIs, die sich über alle Seiten konsistent verhalten,
- und die Möglichkeit, über Python mehr zu tun als „nur" Standardvisualisierung.
Warum das Projekt hier nicht aufhört
Bis hierhin ist das Setup bewusst „nur" ein Reporting-Cockpit: Ich sehe, was in der Vergangenheit passiert ist, und kann Muster im Incident- und Servicemanagement erkennen. In vielen Organisationen endet BI genau an dieser Stelle – die Planung findet dann in einem anderen Tool oder in Excel statt.
Mein Ziel ist es, diesen Bruch perspektivisch zu reduzieren und das Szenario Schritt für Schritt in Richtung XP&A zu erweitern (Extended Planning & Analytics).
Gemeinsame Datenbasis für Reporting & Planung
Der große Vorteil des aktuellen Designs: Die Datenbasis eignet sich nicht nur für Reporting, sondern auch als Grundlage für Planung und Forecasting:
- die Kalenderdimension (
dim_date) bildet eine natürliche Zeitachse für Plan- und Forecastszenarien, - Teams und Users lassen sich direkt als Planungseinheiten nutzen,
- Ticketvolumen, Bearbeitungszeiten und SLA-Raten eignen sich als Treibergrößen für Kapazitätsplanung.
Genau hier setzt die Idee an, eine Planungsplattform wie board anzubinden.
Idee: board als Planungsebene
Technisch könnte das so aussehen:
- Datenanbindung: board liest dieselben Dimensionen (Date, Team, User) und das historische Ticketvolumen aus PostgreSQL oder aus vorbereiteten Views.
- Planungsmodelle: In board werden darauf aufbauend Plan- und Forecastgrößen modelliert – z.B. geplantes Ticketvolumen pro Monat und Team, geplante FTE je Team oder Zielwerte für SLA-Quoten.
- Schreiben von Plandaten: Planwerte werden in eigene Planungs-Tabellen zurückgeschrieben (z.B.
ops_plan_ticket,ops_plan_capacity). - Ist-vs-Plan in Power BI: Power BI kann diese Plan-Tabellen wiederum anbinden und als zusätzliche Faktenebene neben
ops_fact_ticketdarstellen.
Damit entstünde eine Architektur, in der:
- Power BI vor allem die Ist-Daten und Analysen zeigt,
- board die Planungs- und Simulationslogik abbildet,
- und beide sich eine konsistente Datenbasis teilen.
Mögliche Anwendungsszenarien
Einige Szenarien, die sich auf dieser Basis abbilden ließen:
- Kapazitätsplanung je Team: Wie viele FTE brauche ich pro Team, um bei einem erwarteten Ticketvolumen eine bestimmte SLA-Quote zu halten?
- Volumenszenarien: Was passiert mit Durchlaufzeiten und SLA-Raten, wenn das Volumen um 10, 20 oder 50 % steigt?
- Organisationsänderungen: Wie wirkt es sich aus, wenn Teams zusammengelegt oder neu geschnitten werden?
- „Was-wäre-wenn"-Simulationen: Kombination aus geänderten Ticketmixen (Priorities, Kategorien) und geplanter Kapazität.
Ein wichtiger Punkt: All diese Fragestellungen lassen sich nur sinnvoll beantworten, wenn die Ist-Daten und KPIs stabil definiert sind – genau das war der Fokus dieses ersten Projektteils.
Wie es konkret weitergehen soll
Für die nächsten Schritte plane ich:
- Zusätzliche KPIs und Seiten im Power-BI-Cockpit (z.B. Reopen-Rate, Backlog, Projekt- oder Release-Bezug),
- Definition einer sauberen Schnittstelle für Planungsdaten (Tabellenstruktur, Granularität, Schlüssel),
- einen ersten Prototypen in board, der das Ticketvolumen pro Monat und Team plant und Ist-/Plan-Differenzen berechnet.
Sobald dieser Prototyp steht, wird es einen separaten technischen Beitrag geben, in dem ich die Integration Power BI ↔ PostgreSQL ↔ board im Detail dokumentiere – inklusive Datenflüssen, Modellierung und Beispiel-Screenshots.
Warum ich den Ausblick schon jetzt skizziere
Auch wenn vieles davon noch Zukunftsmusik ist, hilft mir dieser Ausblick, wichtige Designentscheidungen früh bewusst zu treffen:
- Primärschlüssel und Granularität so wählen, dass sie auch für Planung und Forecasting taugen,
- KPIs so definieren, dass sie sich für Ist- und Planwerte gleichermaßen eignen,
- und schon jetzt darauf zu achten, dass die Architektur erweiterbar bleibt – anstatt später alles „zurechtbiegen" zu müssen.
Genau deshalb fühlt sich dieses Projekt für mich nicht wie ein einmaliges Bastel-Dashboard an, sondern wie der Startpunkt einer kleinen, aber ernst gemeinten XP&A-Spielwiese.