
Prolog: Manuelles Deployment ist ein Risiko
Jedes manuelle Deployment ist eine Fehlerquelle: ein vergessener Build-Step, ein übersprungener Test, eine falsche Konfiguration. CI/CD (Continuous Integration / Continuous Deployment) eliminiert diese Risiken: Jeder git push triggert automatisch Build, Test, Security-Check und Deployment — reproduzierbar, nachvollziehbar, fehlerfrei. In diesem Artikel bauen wir eine komplette CI/CD-Pipeline auf — von GitHub Actions über Testing-Strategien bis zu Zero-Downtime-Deployments.
Das Ergebnis: Code-Änderungen erreichen Production in unter 15 Minuten, vollautomatisch, mit Sicherheitsnetz und Rollback-Option.
Kapitel 1: Die Pipeline — Vom Push zur Production
Eine CI/CD-Pipeline besteht aus sechs Stufen, die sequenziell durchlaufen werden: Code Push (der Trigger), Build (Dependencies installieren, kompilieren), Test (Unit-, Integration-, E2E-Tests), Security (SAST, Dependency Audit), Staging (Deploy in eine Testumgebung) und Deploy (Production Release). Scheitert eine Stufe, stoppt die Pipeline — und du bekommst sofort Feedback.
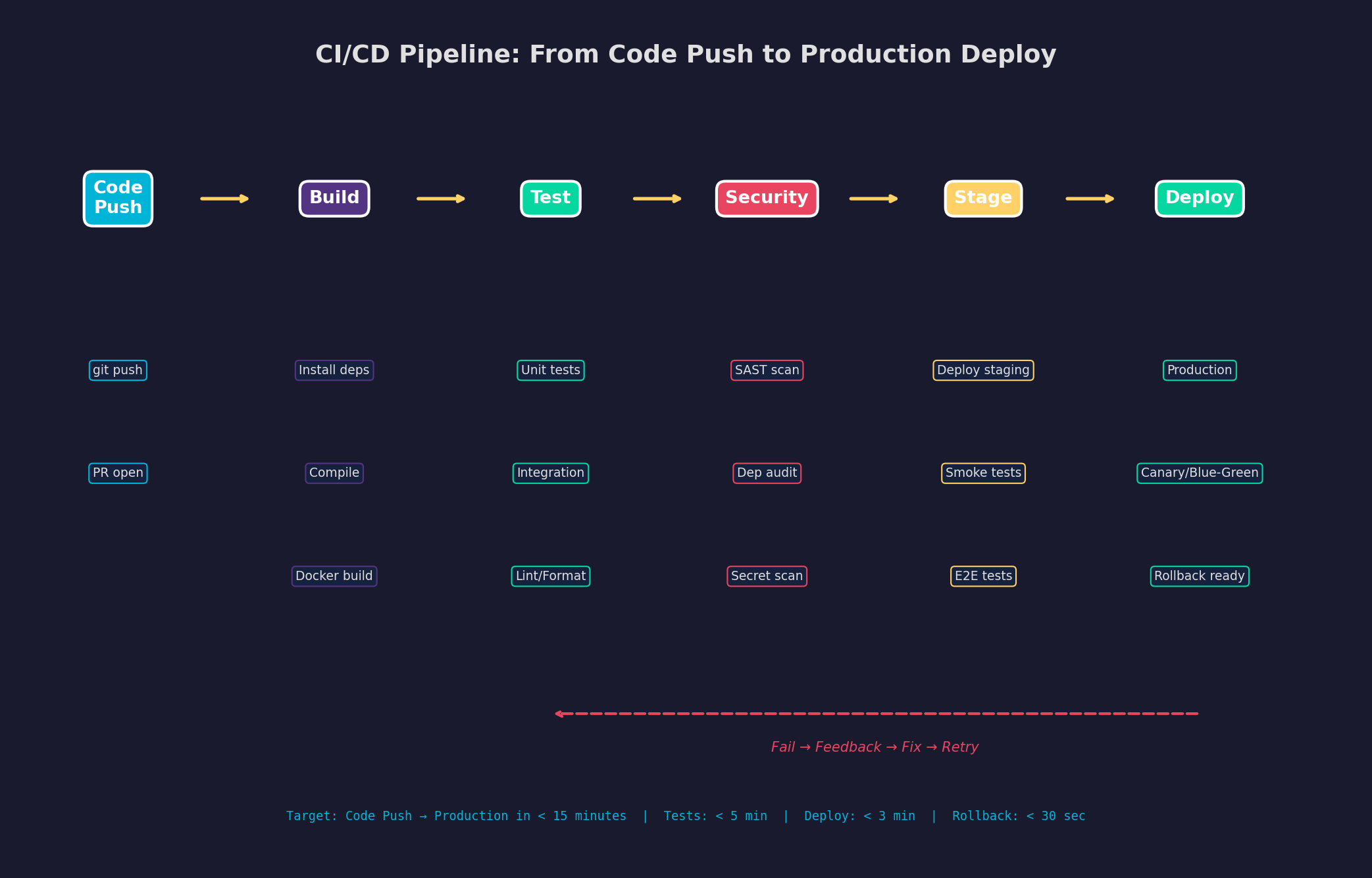
Der kritische Punkt ist Geschwindigkeit: Je länger die Pipeline braucht, desto seltener committen Entwickler, desto größer werden die Änderungen, desto schwieriger das Debugging. Eine gute Pipeline gibt innerhalb von 5 Minuten Feedback zu Tests und innerhalb von 15 Minuten ein Production-Deployment. Alles darüber bremst den Entwicklungsfluss.
Kapitel 2: GitHub Actions — Workflow-Konfiguration
GitHub Actions ist der De-facto-Standard für CI/CD bei Open-Source- und kleinen Teams. Workflows werden in YAML definiert (.github/workflows/), sind event-basiert (push, PR, schedule) und laufen auf GitHub-hosted oder self-hosted Runners. Die Lernkurve ist flach, die Integration mit GitHub nahtlos.

Wichtige Patterns: (1) Matrix Builds — teste gegen mehrere Python-Versionen parallel. (2) Caching — actions/cache speichert pip-Dependencies zwischen Runs (~87% schneller). (3) Secrets — SSH-Keys, API-Tokens und Passwörter via ${{ secrets.DEPLOY_KEY }} injizieren, niemals hardcoden. (4) Conditional Deployment — if: github.ref == 'refs/heads/main' stellt sicher, dass nur der main-Branch deployed wird. (5) Artifacts — Test-Coverage und Build-Artefakte hochladen für Post-Mortem-Analyse.
Kapitel 3: Testing-Strategie — Die Test-Pyramide
Tests sind das Sicherheitsnetz deiner Pipeline. Ohne Tests ist CI/CD wertlos — du deployst nur schneller Bugs. Die Test-Pyramide definiert die Balance: Viele schnelle Unit Tests (75%), weniger Integration Tests (20%), und nur wenige langsame E2E Tests (5%). Die Pyramide optimiert gleichzeitig Abdeckung und Geschwindigkeit.
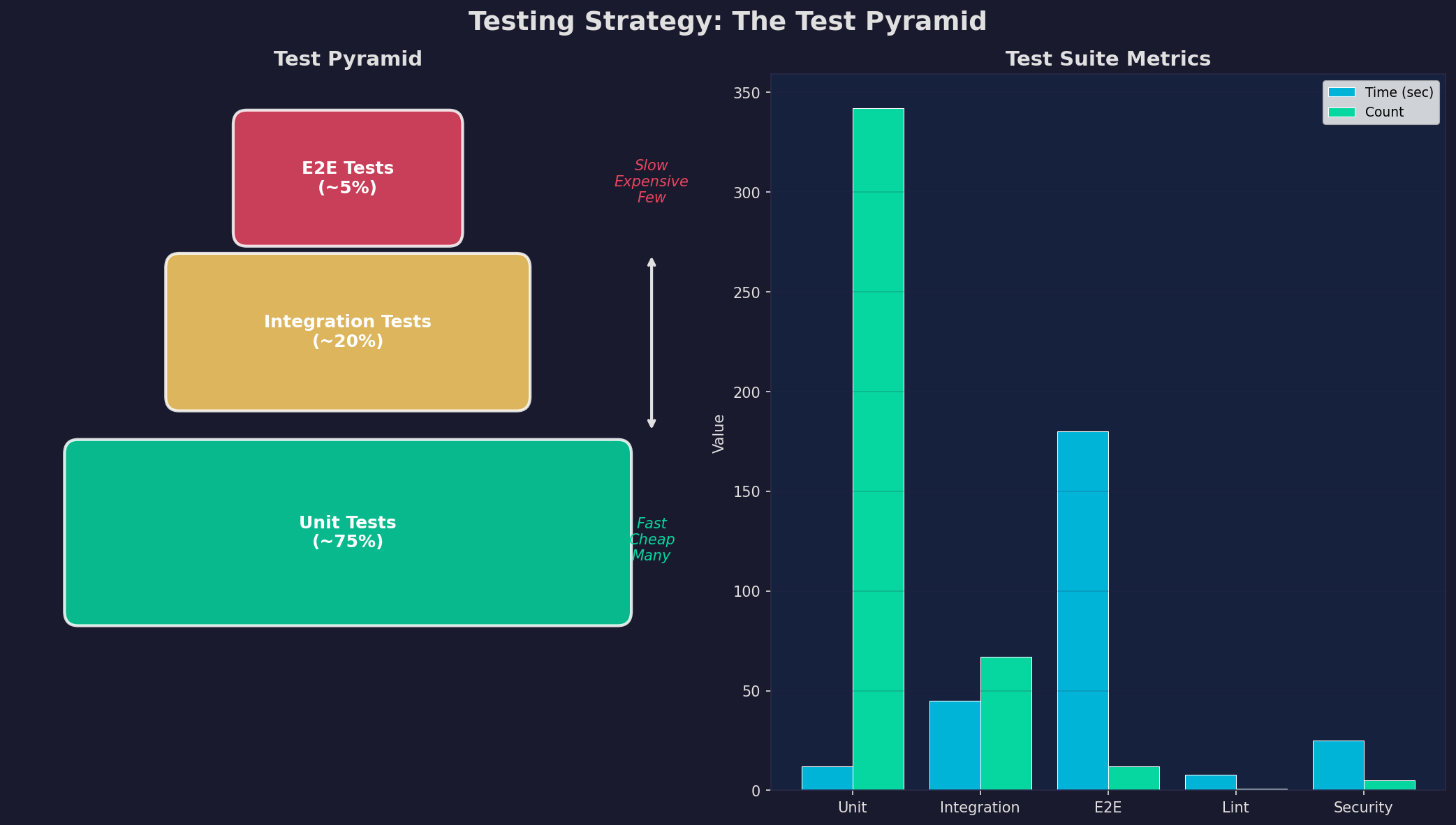
Praxis-Tipps: (1) Unit Tests sollten keine Datenbank brauchen — Mocks und Fakes für externe Dependencies. (2) Integration Tests testen echte Interaktionen — API-Endpoints gegen eine Test-Datenbank. (3) E2E Tests nur für kritische User-Journeys — Login, Checkout, Core-Workflow. (4) Code Coverage als Metrik, nicht als Ziel — 80% ist gut, 100% ist unrealistisch und teuer. (5) Tests müssen deterministisch sein — keine Abhängigkeiten von Uhrzeit, Netzwerk oder externen APIs.
Kapitel 4: Deployment-Strategien — Zero-Downtime-Releases
Ein Deployment darf niemals Downtime verursachen. Nutzer merken es sofort, Suchmaschinen bestrafen es, und Umsatz geht verloren. Es gibt vier gängige Strategien, jede mit eigenen Trade-offs bezüglich Risiko, Rollback-Geschwindigkeit und Komplexität.

Meine Empfehlung für einen einzelnen Linux-Server: Blue-Green Deployment. Du hast zwei Docker-Compose-Stacks (blue und green), der Nginx-Reverse-Proxy zeigt auf den aktiven Stack. Beim Deployment startest du den inaktiven Stack mit der neuen Version, prüfst die Health-Checks, und switchst den Nginx-Upstream. Bei Problemen: sofortiger Switch zurück — Rollback in unter 30 Sekunden.
Kapitel 5: Build-Optimierung — Schnellere Feedback-Loops
Die Pipeline ist nur so gut wie ihre Geschwindigkeit. Eine 10-Minuten-Pipeline fühlt sich an wie eine 10-Sekunden-Pipeline — man wartet einfach. Eine 30-Minuten-Pipeline zerstört den Flow. Optimierung bedeutet: Caching, Parallelisierung und inkrementelle Builds.
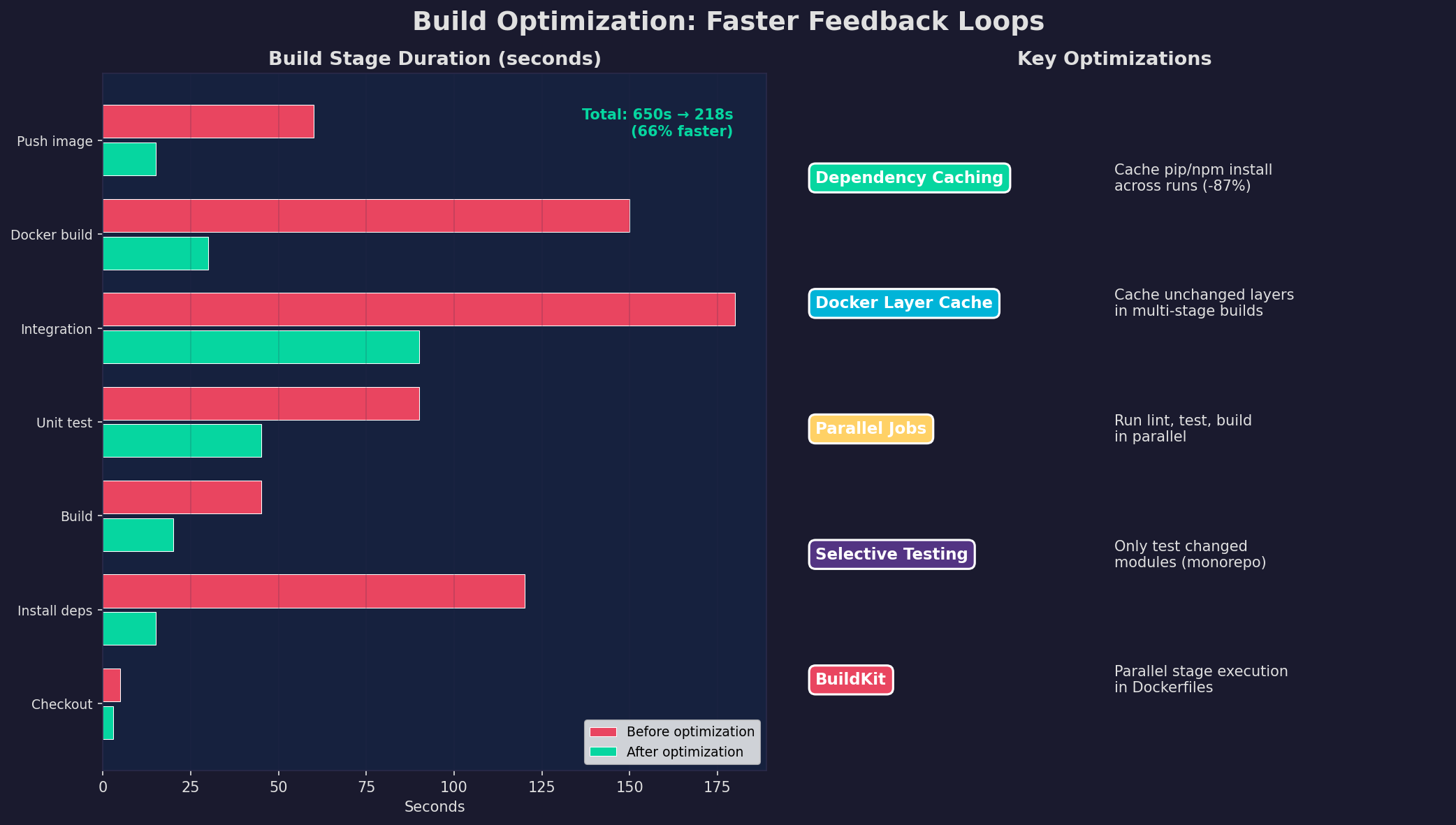
Die größten Hebel: (1) Dependency Caching — pip install cached in GitHub Actions: von 120s auf 15s. (2) Docker Layer Cache — unveränderte Layer werden nicht neu gebaut: Docker Build von 150s auf 30s. (3) Parallele Jobs — Lint, Test und Security gleichzeitig statt nacheinander. (4) Selective Testing — in Monorepos nur geänderte Module testen. (5) BuildKit — parallele Stage-Execution in Multi-Stage Dockerfiles. Zusammen: 66% schnellere Pipeline.
Kapitel 6: Pipeline-Metriken — Messen, was zählt
Die vier DORA-Metriken (DevOps Research and Assessment) messen die Leistung deiner CI/CD-Pipeline: Deploy Frequency (wie oft?), Lead Time (wie schnell?), Change Failure Rate (wie zuverlässig?) und Mean Time to Recovery (wie schnell repariert?). Elite-Teams deployen mehrmals täglich mit einer Lead Time unter einer Stunde.
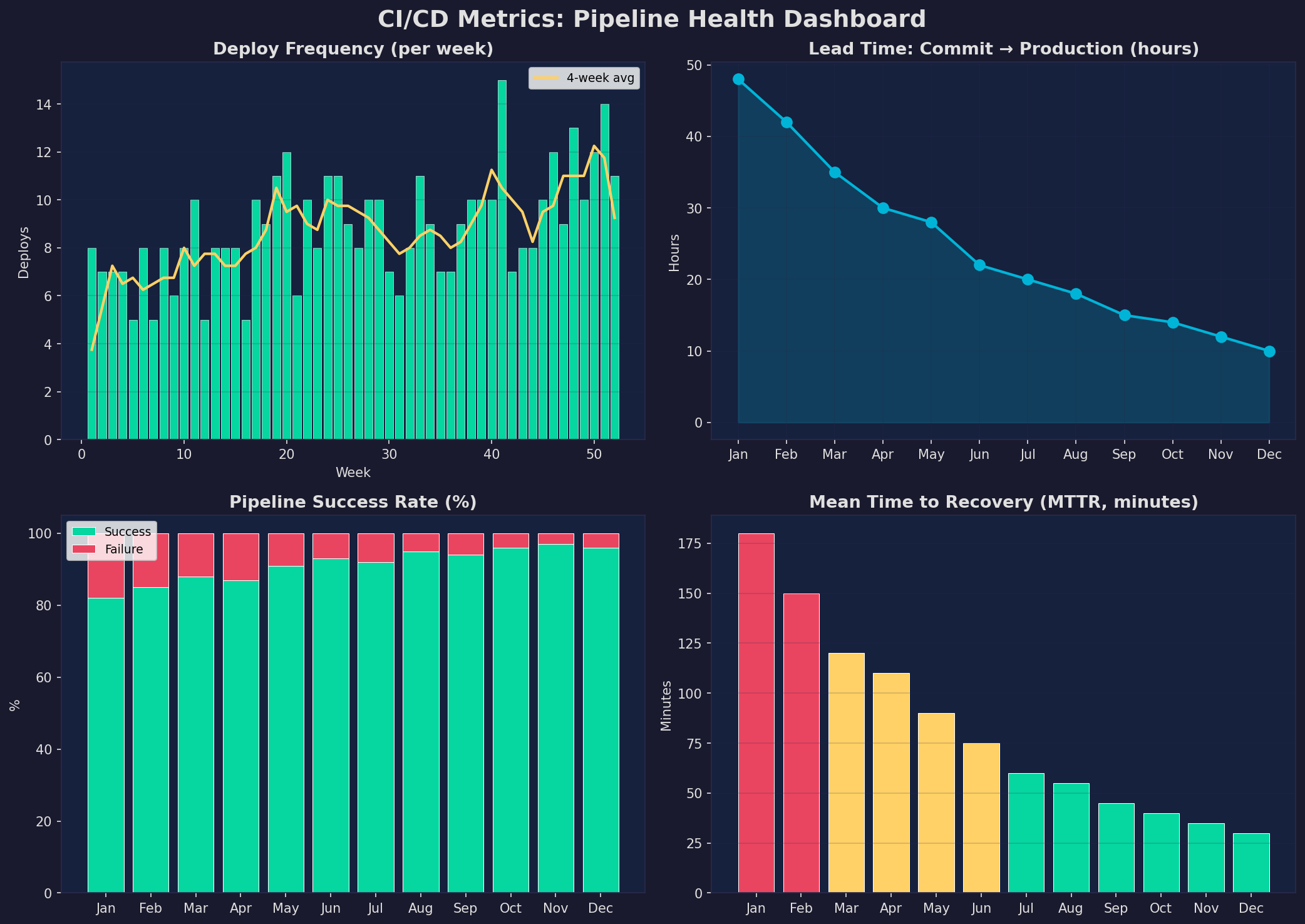
Praktische Umsetzung: (1) Tracke jede Metrik automatisch — GitHub Actions exportiert Dauer und Status. (2) Setze Ziele: Deploy Frequency >5/Woche, Lead Time <24h, Failure Rate <5%, MTTR <60min. (3) Analysiere Trends — eine steigende Failure Rate deutet auf technische Schulden hin. (4) Teile die Metriken mit dem Team — Transparenz motiviert Verbesserung.
Epilog: CI/CD ist Infrastruktur, kein Luxus
CI/CD ist keine optionale Nettigkeit — es ist Infrastruktur, die den Unterschied zwischen einem Hobby-Projekt und einem professionellen Setup macht. Die initiale Einrichtung kostet einen Tag, die Zeitersparnis beträgt Hunderte Stunden pro Jahr. Jeder git push wird automatisch getestet, gescannt und deployed. Kein manueller Schritt, kein Vergessen, kein „it works on my machine". Automatisiere alles.
Zitationen
- Forsgren, N. et al. (2018). Accelerate: The Science of Lean Software and DevOps. IT Revolution Press.
- Humble, J. & Farley, D. (2010). Continuous Delivery. Addison-Wesley.
- Kim, G. et al. (2016). The DevOps Handbook. IT Revolution Press.
- GitHub (2024). GitHub Actions Documentation. docs.github.com/actions
- DORA Team (2023). State of DevOps Report 2023. cloud.google.com/devops
Fazit
Eine CI/CD-Pipeline transformiert den Entwicklungsprozess: Automatisches Testing (Test-Pyramide), Zero-Downtime-Deployments (Blue-Green/Canary), Build-Optimierung (Caching, Parallelisierung) und Metriken-getriebene Verbesserung (DORA-Metriken). Jedes Kapitel ist ein konkreter Schritt — zusammen ergeben sie eine Pipeline, die schnell, zuverlässig und wartbar ist.
Dokumentation
| Parameter | Wert |
|---|---|
| CI/CD Platform | GitHub Actions (hosted) |
| Pipeline-Dauer | < 15 min (Push → Production) |
| Test-Suite | 342 Unit + 67 Integration + 12 E2E |
| Coverage-Ziel | 80% (Lines) |
| Deployment | Blue-Green (Zero Downtime) |
| Rollback-Zeit | < 30 Sekunden |
| Deploy-Frequenz | > 5x/Woche |
| MTTR-Ziel | < 60 Minuten |
Prologue: Manual Deployment Is a Risk
Every manual deployment is a source of error: a forgotten build step, a skipped test, a wrong configuration. CI/CD (Continuous Integration / Continuous Deployment) eliminates these risks: Every git push automatically triggers build, test, security check, and deployment — reproducible, traceable, error-free. In this article, we build a complete CI/CD pipeline — from GitHub Actions through testing strategies to zero-downtime deployments.
The result: Code changes reach production in under 15 minutes, fully automated, with safety net and rollback option.
Chapter 1: The Pipeline — From Push to Production
A CI/CD pipeline consists of six stages executed sequentially: Code Push (the trigger), Build (install dependencies, compile), Test (unit, integration, E2E tests), Security (SAST, dependency audit), Staging (deploy to test environment), and Deploy (production release). If any stage fails, the pipeline stops — and you get immediate feedback.
The critical factor is speed: The longer the pipeline takes, the less frequently developers commit, the larger the changes, the harder the debugging. A good pipeline gives feedback within 5 minutes for tests and within 15 minutes a production deployment. Anything longer slows down the development flow.
Chapter 2: GitHub Actions — Workflow Configuration
GitHub Actions is the de facto standard for CI/CD in open-source and small teams. Workflows are defined in YAML (.github/workflows/), are event-based (push, PR, schedule), and run on GitHub-hosted or self-hosted runners. The learning curve is shallow, the integration with GitHub seamless.
Important patterns: (1) Matrix Builds — test against multiple Python versions in parallel. (2) Caching — actions/cache stores pip dependencies between runs (~87% faster). (3) Secrets — SSH keys, API tokens, and passwords via ${{ secrets.DEPLOY_KEY }}, never hardcode. (4) Conditional Deployment — if: github.ref == 'refs/heads/main' ensures only the main branch gets deployed. (5) Artifacts — upload test coverage and build artifacts for post-mortem analysis.
Chapter 3: Testing Strategy — The Test Pyramid
Tests are the safety net of your pipeline. Without tests, CI/CD is worthless — you're just deploying bugs faster. The test pyramid defines the balance: Many fast unit tests (75%), fewer integration tests (20%), and only a few slow E2E tests (5%). The pyramid optimizes both coverage and speed simultaneously.
Practical tips: (1) Unit tests should need no database — use mocks and fakes for external dependencies. (2) Integration tests test real interactions — API endpoints against a test database. (3) E2E tests only for critical user journeys — login, checkout, core workflow. (4) Code coverage as a metric, not a goal — 80% is good, 100% is unrealistic and expensive. (5) Tests must be deterministic — no dependencies on time, network, or external APIs.
Chapter 4: Deployment Strategies — Zero-Downtime Releases
A deployment must never cause downtime. Users notice immediately, search engines penalize it, and revenue is lost. There are four common strategies, each with its own trade-offs regarding risk, rollback speed, and complexity.
My recommendation for a single Linux server: Blue-Green Deployment. You have two Docker Compose stacks (blue and green), the Nginx reverse proxy points to the active stack. On deployment, you start the inactive stack with the new version, check health checks, and switch the Nginx upstream. On problems: instant switch back — rollback in under 30 seconds.
Chapter 5: Build Optimization — Faster Feedback Loops
The pipeline is only as good as its speed. A 10-minute pipeline feels like a 10-second pipeline — you just wait. A 30-minute pipeline destroys flow. Optimization means: caching, parallelization, and incremental builds.
The biggest levers: (1) Dependency Caching — pip install cached in GitHub Actions: from 120s to 15s. (2) Docker Layer Cache — unchanged layers aren't rebuilt: Docker build from 150s to 30s. (3) Parallel Jobs — lint, test, and security simultaneously instead of sequentially. (4) Selective Testing — in monorepos, only test changed modules. (5) BuildKit — parallel stage execution in multi-stage Dockerfiles. Combined: 66% faster pipeline.
Chapter 6: Pipeline Metrics — Measure What Matters
The four DORA metrics (DevOps Research and Assessment) measure your CI/CD pipeline's performance: Deploy Frequency (how often?), Lead Time (how fast?), Change Failure Rate (how reliable?), and Mean Time to Recovery (how quickly repaired?). Elite teams deploy multiple times daily with lead times under one hour.
Practical implementation: (1) Track every metric automatically — GitHub Actions exports duration and status. (2) Set targets: deploy frequency >5/week, lead time <24h, failure rate <5%, MTTR <60min. (3) Analyze trends — a rising failure rate indicates technical debt. (4) Share metrics with the team — transparency motivates improvement.
Epilogue: CI/CD Is Infrastructure, Not Luxury
CI/CD isn't an optional nicety — it's infrastructure that makes the difference between a hobby project and a professional setup. Initial setup costs one day, the time savings amount to hundreds of hours per year. Every git push is automatically tested, scanned, and deployed. No manual steps, no forgetting, no "it works on my machine." Automate everything.
Citations
- Forsgren, N. et al. (2018). Accelerate: The Science of Lean Software and DevOps. IT Revolution Press.
- Humble, J. & Farley, D. (2010). Continuous Delivery. Addison-Wesley.
- Kim, G. et al. (2016). The DevOps Handbook. IT Revolution Press.
- GitHub (2024). GitHub Actions Documentation. docs.github.com/actions
- DORA Team (2023). State of DevOps Report 2023. cloud.google.com/devops
Conclusion
A CI/CD pipeline transforms the development process: Automated testing (test pyramid), zero-downtime deployments (blue-green/canary), build optimization (caching, parallelization), and metrics-driven improvement (DORA metrics). Each chapter is a concrete step — together they form a pipeline that is fast, reliable, and maintainable.
Documentation
| Parameter | Value |
|---|---|
| CI/CD Platform | GitHub Actions (hosted) |
| Pipeline Duration | < 15 min (push → production) |
| Test Suite | 342 unit + 67 integration + 12 E2E |
| Coverage Target | 80% (lines) |
| Deployment | Blue-Green (zero downtime) |
| Rollback Time | < 30 seconds |
| Deploy Frequency | > 5x/week |
| MTTR Target | < 60 minutes |