
Abstract
Quarto ist das Open-Source-Publikationssystem der nächsten Generation für wissenschaftliches und technisches Schreiben. Als Nachfolger von R Markdown unterstützt es nativ R, Python, Julia und Observable – in einem einzigen Dokument. Für Bioinformatik-Teams, die reproduzierbare Analyseberichte, Manuskripte und interaktive Dashboards aus ihren Pipelines generieren müssen, ersetzt Quarto die Flickenteppich-Lösung aus Jupyter-Notebooks, R-Markdown-Dateien und manuellen Word-Dokumenten durch einen einheitlichen Workflow.
Typisches Projektszenario
Ein klinisches Bioinformatik-Core erstellt monatliche Qualitätsberichte für ein NGS-Labor: Sequenzierungsstatistiken aus der LIMS-Datenbank (Python/pandas), Qualitätsmetriken aus MultiQC-Daten (Python), differenzielle Expressionsanalysen (R/DESeq2) und Variant-Calling-Zusammenfassungen (Python/cyvcf2). Bisher: vier separate Skripte, manuelle Copy-Paste in PowerPoint. Mit Quarto: ein einziges .qmd-Dokument mit R- und Python-Codeblöcken, parametrisiert über den Berichtsmonat, automatisch gerendert als HTML-Report mit interaktiven Plots und als PDF für die Klinikleitung.
Welches Problem löst Quarto?
- Polyglotte Analysen: Moderne Bioinformatik nutzt R und Python. Quarto erlaubt beide Sprachen im selben Dokument – R-Chunks für statistische Modelle, Python-Chunks für Datenverarbeitung und Visualisierung. Variablen können über
reticulatezwischen den Sprachen geteilt werden. - Format-Flexibilität: Dasselbe Quelldokument rendert zu HTML (interaktiv, mit Plotly/DT), PDF (LaTeX-Qualität für Publikationen), Word (für nicht-technische Stakeholder), Präsentationen (Reveal.js) und Websites (Quarto Books/Blogs).
- Reproduzierbarkeit: Code, Daten und Prosa leben im selben Dokument.
freeze: truespeichert berechnete Outputs, sodass der Bericht auch ohne die Originaldaten erneut gerendert werden kann._quarto.ymldefiniert Projektstruktur und Rendering-Optionen zentral.
Warum Teams Quarto einsetzen
- Sprachagnostisch: R, Python, Julia, Observable – Quarto bindet sich nicht an eine Sprache, sondern nutzt knitr (R) oder Jupyter (Python) als Engines.
- IDE-Integration: Native Unterstützung in RStudio, VS Code und JupyterLab – mit Preview, Autocompletion und Chunk-Ausführung.
- Wissenschaftliche Features: Cross-Referencing, Zitationen (BibTeX), Gleichungs-Nummerierung, Abbildungsbeschriftungen, Callout-Blöcke, Theorem-Umgebungen – alles nativ.
- Parametrisierte Reports:
params:im YAML-Header ermöglichen die Erstellung von Berichten in einer Schleife – ein Template, 50 Patientenberichte. - CI/CD-Integration:
quarto renderlässt sich in GitHub Actions, GitLab CI und Snakemake-Pipelines einbinden.
Quarto-Architektur
Quarto verarbeitet .qmd-Dateien in einer dreistufigen Pipeline, deren Verständnis für die Fehlerdiagnose essentiell ist. Stufe 1 (Execution): Code-Chunks werden durch die jeweilige Engine ausgeführt – knitr für R, Jupyter für Python/Julia. Die Ausgabe (Text, Tabellen, Plots) wird als Markdown mit eingebetteten Ergebnissen gespeichert. Stufe 2 (Pandoc): Das Markdown wird durch Pandoc verarbeitet, das Cross-References auflöst, Zitationen einfügt und die Dokumentstruktur erstellt. Lua-Filter ermöglichen benutzerdefinierte Transformationen. Stufe 3 (Output): Je nach Format wird HTML (mit Bootstrap/Themes), PDF (via LaTeX/TinyTeX) oder Word (via Pandoc-Template) generiert.
Die freeze-Option ist für reproduzierbare Berichte zentral: freeze: auto führt Code nur aus, wenn sich die Quelldatei geändert hat, und speichert die Ergebnisse in _freeze/. Das ermöglicht das Rendering auf Systemen ohne installierte R/Python-Umgebungen – ideal für CI/CD-Pipelines, die nur Pandoc und Quarto benötigen.
Quarto-Dokument: Beispiel
---
title: "NGS-Qualitätsbericht"
author: "Bioinformatics Core"
date: today
format:
html:
toc: true
code-fold: true
theme: cosmo
pdf:
documentclass: scrartcl
papersize: a4
params:
month: "2024-01"
project: "PROJ-042"
execute:
echo: false
warning: false
bibliography: references.bib
---
#| label: fig-qc-metrics
#| fig-cap: "Sequenzierungsqualität pro Sample"
#| fig-width: 10
#| fig-height: 6
import pandas as pd
import plotly.express as px
qc = pd.read_csv(f"data/multiqc_{params['month']}.csv")
fig = px.box(qc, x="sample", y="mean_quality",
color="run_id",
title=f"Qualitätsscores {params['month']}")
fig.show()
#| label: fig-de-volcano
#| fig-cap: "Differenzielle Expression: Behandlung vs. Kontrolle"
library(DESeq2)
library(EnhancedVolcano)
dds <- readRDS(paste0("data/deseq2_", params$project, ".rds"))
res <- results(dds, contrast = c("condition", "treated", "control"))
EnhancedVolcano(res, lab = rownames(res),
x = 'log2FoldChange', y = 'padj',
pCutoff = 0.05, FCcutoff = 1)
Diagnostische Plots
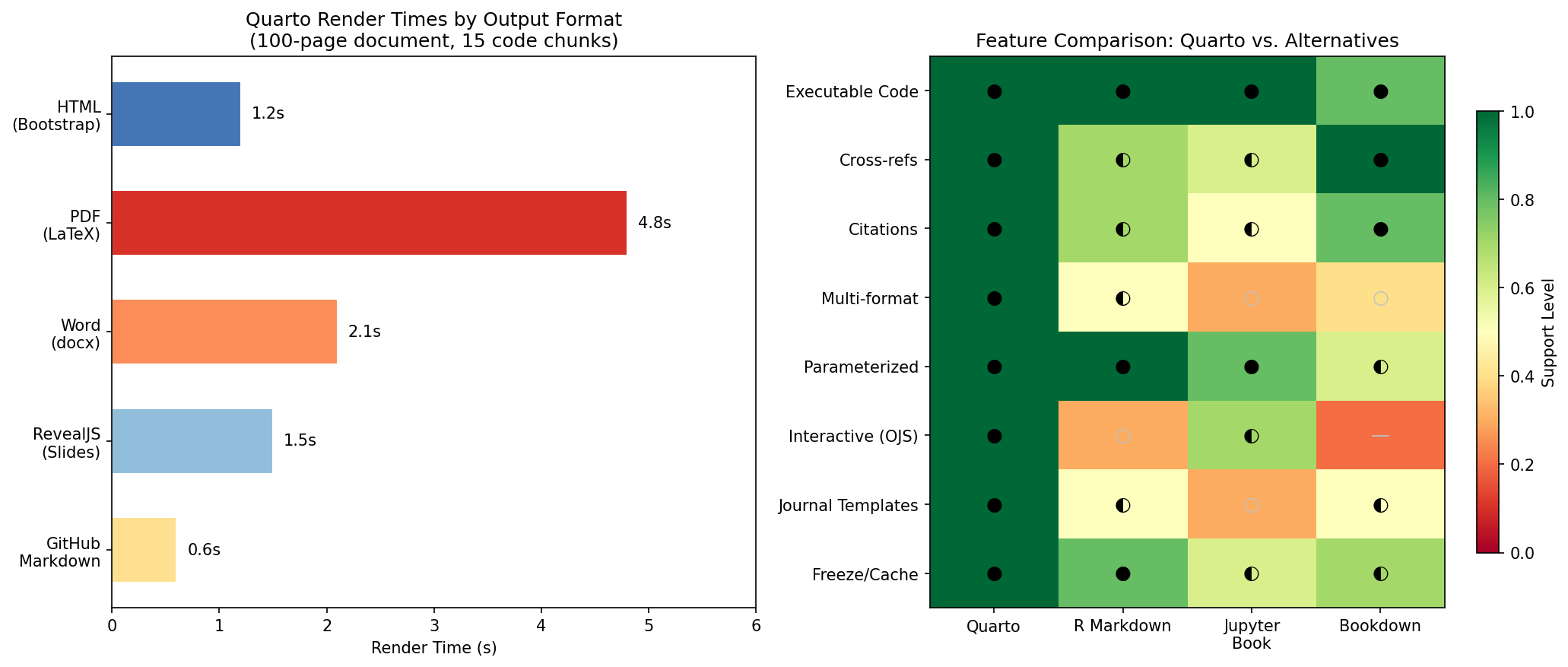
Vergleich mit Alternativen
| Merkmal | Quarto | R Markdown | Jupyter Notebook | Typst |
|---|---|---|---|---|
| Sprachen | R, Python, Julia, OJS | R (Python via reticulate) | Python (R via rpy2) | Typst-eigene Sprache |
| Output-Formate | HTML, PDF, Word, Reveal.js, Websites | HTML, PDF, Word | HTML, PDF (nbconvert) | |
| Cross-References | Nativ | Über bookdown | Nicht nativ | Nativ |
| Parametrisiert | params: im YAML | params: im YAML | papermill | Nein |
| Versionskontrolle | Gut (Plaintext .qmd) | Gut (Plaintext .Rmd) | Schlecht (JSON-Diffs) | Gut (Plaintext) |
| Freeze/Cache | freeze: auto | cache: true (knitr) | Manuell | Nicht verfügbar |
Fortgeschrittene Workflows
Parametrisierte Batch-Reports sind für klinische Labore besonders relevant. Ein einziges Quarto-Template wird mit verschiedenen Parametern in einer Schleife gerendert: quarto render report.qmd -P month:2024-01 -P project:PROJ-042. In R kann das über quarto_render() oder in Snakemake über eine parametrisierte Rule automatisiert werden. Jeder Bericht erhält seine eigenen Daten, Plots und Statistiken – aus einem Template.
Quarto Extensions erweitern die Funktionalität: quarto-webr ermöglicht interaktive R-Sessions direkt im Browser (ohne Server), quarto-pyodide das Gleiche für Python. Für wissenschaftliche Publikationen gibt es Journal-Templates (PLOS, Elsevier, JASA), die das Manuskript direkt im Einreichungsformat rendern. Lua-Filter erlauben benutzerdefinierte Pandoc-Transformationen – etwa das automatische Einfügen von Supplementary-Tabellen-Nummern.
Quarto Manuscripts (seit Quarto 1.4) unterstützen den vollständigen wissenschaftlichen Publikationsworkflow: Haupttext + Supplementary als verknüpfte Dokumente, Notebook-Einbettung für zusätzliche Analysen, und automatische Querverweis-Auflösung über Dokumente hinweg. Das ermöglicht es, ein Manuskript als reproduzierbares Quarto-Projekt zu pflegen – von der Erstanalyse bis zur Revision.
Zitationen
- Allaire JJ et al. (2024). “Quarto: An Open-Source Scientific and Technical Publishing System.” quarto.org
- Xie Y, Allaire JJ, Grolemund G (2018). R Markdown: The Definitive Guide. Chapman & Hall/CRC.
- Lowndes JSS et al. (2017). “Our path to better science in less time using open data science tools.” Nature Ecology & Evolution, 1, 0160.
Fazit
Quarto ist die Zukunft des wissenschaftlichen Publishings in der Bioinformatik. Es löst das zentrale Problem polyglotter Analyse-Pipelines: ein Format für R und Python, ein Dokument für HTML und PDF, ein Workflow für Exploration und Publikation. Limitierungen: (1) Die Execution-Geschwindigkeit hängt von der Engine ab – Jupyter-Startup kann bei großen Python-Umgebungen langsam sein. (2) Komplexe LaTeX-Layouts erfordern nach wie vor LaTeX-Kenntnisse. (3) Das Ökosystem ist jünger als R Markdown und einige Nischen-Extensions fehlen noch. Aber für 90% der bioinformatischen Reporting-Bedürfnisse ist Quarto die beste verfügbare Lösung.
Dokumentation
Abstract
Quarto is the next-generation open-source publishing system for scientific and technical writing. As the successor to R Markdown, it natively supports R, Python, Julia, and Observable—in a single document. For bioinformatics teams needing to generate reproducible analysis reports, manuscripts, and interactive dashboards from their pipelines, Quarto replaces the patchwork solution of Jupyter notebooks, R Markdown files, and manual Word documents with a unified workflow.
Typical Project Scenario
A clinical bioinformatics core creates monthly quality reports for an NGS lab: sequencing statistics from the LIMS database (Python/pandas), quality metrics from MultiQC data (Python), differential expression analyses (R/DESeq2), and variant calling summaries (Python/cyvcf2). Previously: four separate scripts, manual copy-paste into PowerPoint. With Quarto: a single .qmd document with R and Python code blocks, parameterized by report month, automatically rendered as an HTML report with interactive plots and as PDF for clinic management.
What Problem Does Quarto Solve?
- Polyglot analyses: Modern bioinformatics uses R and Python. Quarto allows both languages in the same document—R chunks for statistical models, Python chunks for data processing and visualization. Variables can be shared between languages via
reticulate. - Format flexibility: The same source document renders to HTML (interactive, with Plotly/DT), PDF (LaTeX quality for publications), Word (for non-technical stakeholders), presentations (Reveal.js), and websites (Quarto Books/Blogs).
- Reproducibility: Code, data, and prose live in the same document.
freeze: truesaves computed outputs so the report can be re-rendered without original data._quarto.ymldefines project structure and rendering options centrally.
Why Teams Choose Quarto
- Language-agnostic: R, Python, Julia, Observable—Quarto doesn’t bind to a language but uses knitr (R) or Jupyter (Python) as engines.
- IDE integration: Native support in RStudio, VS Code, and JupyterLab—with preview, autocompletion, and chunk execution.
- Scientific features: Cross-referencing, citations (BibTeX), equation numbering, figure captions, callout blocks, theorem environments—all native.
- Parameterized reports:
params:in the YAML header enables report creation in a loop—one template, 50 patient reports. - CI/CD integration:
quarto renderintegrates into GitHub Actions, GitLab CI, and Snakemake pipelines.
Quarto Architecture
Quarto processes .qmd files in a three-stage pipeline whose understanding is essential for debugging. Stage 1 (Execution): Code chunks are executed by the respective engine—knitr for R, Jupyter for Python/Julia. Output (text, tables, plots) is saved as Markdown with embedded results. Stage 2 (Pandoc): The Markdown is processed by Pandoc, which resolves cross-references, inserts citations, and creates the document structure. Lua filters enable custom transformations. Stage 3 (Output): Depending on format, HTML (with Bootstrap/themes), PDF (via LaTeX/TinyTeX), or Word (via Pandoc template) is generated.
The freeze option is central for reproducible reports: freeze: auto executes code only when the source file has changed and saves results in _freeze/. This enables rendering on systems without installed R/Python environments—ideal for CI/CD pipelines that only need Pandoc and Quarto.
Quarto Document: Example
---
title: "NGS Quality Report"
author: "Bioinformatics Core"
date: today
format:
html:
toc: true
code-fold: true
theme: cosmo
pdf:
documentclass: scrartcl
papersize: a4
params:
month: "2024-01"
project: "PROJ-042"
execute:
echo: false
warning: false
bibliography: references.bib
---
#| label: fig-qc-metrics
#| fig-cap: "Sequencing quality per sample"
#| fig-width: 10
#| fig-height: 6
import pandas as pd
import plotly.express as px
qc = pd.read_csv(f"data/multiqc_{params['month']}.csv")
fig = px.box(qc, x="sample", y="mean_quality",
color="run_id",
title=f"Quality Scores {params['month']}")
fig.show()
#| label: fig-de-volcano
#| fig-cap: "Differential expression: treatment vs. control"
library(DESeq2)
library(EnhancedVolcano)
dds <- readRDS(paste0("data/deseq2_", params$project, ".rds"))
res <- results(dds, contrast = c("condition", "treated", "control"))
EnhancedVolcano(res, lab = rownames(res),
x = 'log2FoldChange', y = 'padj',
pCutoff = 0.05, FCcutoff = 1)
Diagnostic Plots
Comparison with Alternatives
| Feature | Quarto | R Markdown | Jupyter Notebook | Typst |
|---|---|---|---|---|
| Languages | R, Python, Julia, OJS | R (Python via reticulate) | Python (R via rpy2) | Typst-native language |
| Output formats | HTML, PDF, Word, Reveal.js, Websites | HTML, PDF, Word | HTML, PDF (nbconvert) | |
| Cross-references | Native | Via bookdown | Not native | Native |
| Parameterized | params: in YAML | params: in YAML | papermill | No |
| Version control | Good (plaintext .qmd) | Good (plaintext .Rmd) | Poor (JSON diffs) | Good (plaintext) |
| Freeze/cache | freeze: auto | cache: true (knitr) | Manual | Not available |
Advanced Workflows
Parameterized batch reports are particularly relevant for clinical labs. A single Quarto template is rendered with different parameters in a loop: quarto render report.qmd -P month:2024-01 -P project:PROJ-042. In R, this can be automated via quarto_render() or in Snakemake via a parameterized rule. Each report receives its own data, plots, and statistics—from one template.
Quarto Extensions expand functionality: quarto-webr enables interactive R sessions directly in the browser (no server), quarto-pyodide does the same for Python. For scientific publications, journal templates (PLOS, Elsevier, JASA) render manuscripts directly in submission format. Lua filters allow custom Pandoc transformations—such as automatic insertion of supplementary table numbers.
Quarto Manuscripts (since Quarto 1.4) support the complete scientific publication workflow: main text + supplementary as linked documents, notebook embedding for additional analyses, and automatic cross-reference resolution across documents. This enables maintaining a manuscript as a reproducible Quarto project—from initial analysis through revision.
Citations
- Allaire JJ et al. (2024). “Quarto: An Open-Source Scientific and Technical Publishing System.” quarto.org
- Xie Y, Allaire JJ, Grolemund G (2018). R Markdown: The Definitive Guide. Chapman & Hall/CRC.
- Lowndes JSS et al. (2017). “Our path to better science in less time using open data science tools.” Nature Ecology & Evolution, 1, 0160.
Conclusion
Quarto is the future of scientific publishing in bioinformatics. It solves the central problem of polyglot analysis pipelines: one format for R and Python, one document for HTML and PDF, one workflow for exploration and publication. Limitations: (1) Execution speed depends on the engine—Jupyter startup can be slow with large Python environments. (2) Complex LaTeX layouts still require LaTeX knowledge. (3) The ecosystem is younger than R Markdown and some niche extensions are still missing. But for 90% of bioinformatics reporting needs, Quarto is the best available solution.